
 矚目客戶端
矚目客戶端 矚目小T
矚目小T 矚目大板
矚目大板 矚目會(huì)議室系統(tǒng)
矚目會(huì)議室系統(tǒng) 矚目直播
矚目直播
 多媒體通信平臺(tái)
多媒體通信平臺(tái) 多媒體通信終端
多媒體通信終端 多媒體通信軟件
多媒體通信軟件 網(wǎng)絡(luò)音頻處理器
網(wǎng)絡(luò)音頻處理器
 變電站智能巡檢機(jī)器人
變電站智能巡檢機(jī)器人 發(fā)電廠智能巡檢機(jī)器人
發(fā)電廠智能巡檢機(jī)器人 配電室智能巡檢機(jī)器人
配電室智能巡檢機(jī)器人 室內(nèi)工業(yè)智能巡檢機(jī)器人
室內(nèi)工業(yè)智能巡檢機(jī)器人 機(jī)器人遠(yuǎn)程專家診斷協(xié)同平臺(tái)解決方案
機(jī)器人遠(yuǎn)程專家診斷協(xié)同平臺(tái)解決方案





OpenAI 發(fā)現(xiàn)獨(dú)特情感神經(jīng)元,無監(jiān)督學(xué)習(xí)系統(tǒng)表征情感取得突破
時(shí)間:2017-04-08
OpenAI 的研究員今天在博客上宣布,他們開發(fā)了一個(gè)無監(jiān)督學(xué)習(xí)的系統(tǒng),能夠很好地對(duì)情感進(jìn)行表征。在數(shù)據(jù)集 Stanford Sentiment Treebank上,他們獲得了當(dāng)下行業(yè)內(nèi)最高的情感分析準(zhǔn)度。現(xiàn)在論文和代碼已經(jīng)公開。在研究的過程中,他們還發(fā)現(xiàn),算法中實(shí)際上存在著一種高度預(yù)測(cè)情緒值的“情感神經(jīng)元”。研究結(jié)果對(duì)于邁向通用無監(jiān)督表征學(xué)習(xí)是很有希望的一步。
OpenAI:我們開發(fā)了一個(gè)非監(jiān)督的系統(tǒng),能夠很好地表征情感。雖然研究中只是用亞馬遜網(wǎng)站上的評(píng)論進(jìn)行了訓(xùn)練,用于預(yù)測(cè)下一個(gè)字母。
一個(gè)線性模型使用這一表征,在一個(gè)小型但是被深度研究過的數(shù)據(jù)集 Stanford Sentiment Treebank上,獲得了當(dāng)下行業(yè)內(nèi)最高的情感分析準(zhǔn)度( 準(zhǔn)確率達(dá)到91.8%,此前最好的只有90.2%),并且,這一非監(jiān)督式的學(xué)習(xí)系統(tǒng),在性能上也能與此前的監(jiān)督式學(xué)習(xí)系統(tǒng)相媲美,使用的標(biāo)簽樣本要少30-100倍。我們的表征還包含了一個(gè)獨(dú)特的“情感神經(jīng)元”(distinguish emotional neurons),這一神經(jīng)元中包含了幾乎所有的情感信號(hào)。
標(biāo)簽訓(xùn)練樣本
我們的系統(tǒng)擊敗了 Stanford Sentiment Treebank 數(shù)據(jù)集上的最佳的方法,同時(shí)使用的數(shù)據(jù)量有大幅地減少。
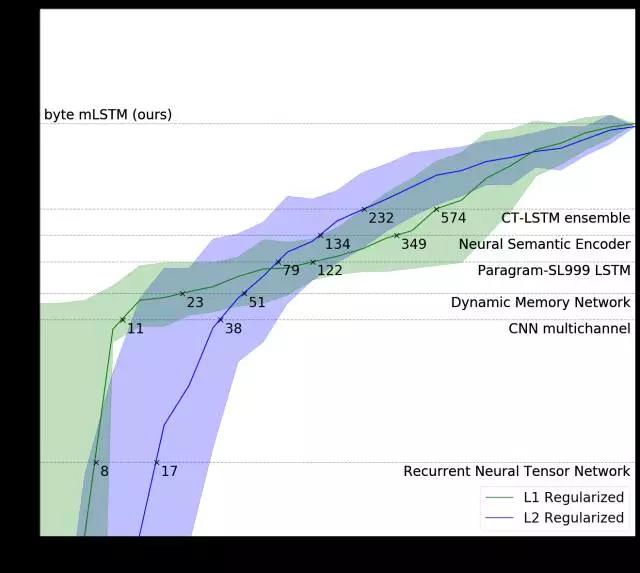
標(biāo)注示例的數(shù)量需要我們模型的兩個(gè)變體(綠色和藍(lán)色線條),以配合完全監(jiān)督的方法,每個(gè)訓(xùn)練有6,920個(gè)例子(虛線)。
我們的L1正則化模型(在亞馬遜評(píng)論中以無監(jiān)督的方式預(yù)先訓(xùn)練)將多通道CNN性能與11個(gè)帶標(biāo)記的示例相匹配,并且使用最先進(jìn)的 CT-LSTM Ensembles與232個(gè)例子相匹配。
我們非常驚訝地看到,我們的模型學(xué)習(xí)了一個(gè)可解釋的特征,并且通過發(fā)現(xiàn)情感概念,簡單地預(yù)測(cè)出亞馬遜評(píng)論中的下一個(gè)字符。我們認(rèn)為這種現(xiàn)象不是我們的模型所特有的,而是一些大型神經(jīng)網(wǎng)絡(luò)的通用性質(zhì),這些大型神經(jīng)網(wǎng)絡(luò)被訓(xùn)練來預(yù)測(cè)其輸入中的下一步或維度。
方法
我們首先在8200萬亞馬遜評(píng)論的語料庫上訓(xùn)練了4,096個(gè)單位的乘法LSTM,以預(yù)測(cè)一小段文本中的下一個(gè)字符。整個(gè)訓(xùn)練在四個(gè)NVIDIA Pascal GPU上花費(fèi)了一個(gè)月的時(shí)間,我們的模型處理速度為每秒12,500個(gè)字符。
這4,096個(gè)單位(只是浮標(biāo)的向量)可以被認(rèn)為是表示模型讀取的字符串的特征向量。在訓(xùn)練mLSTM后,我們采用這些單位的線性組合將模型轉(zhuǎn)換為情感分類器,通過可用的監(jiān)督數(shù)據(jù)學(xué)習(xí)組合的權(quán)重。
獨(dú)一無二的情感神經(jīng)元
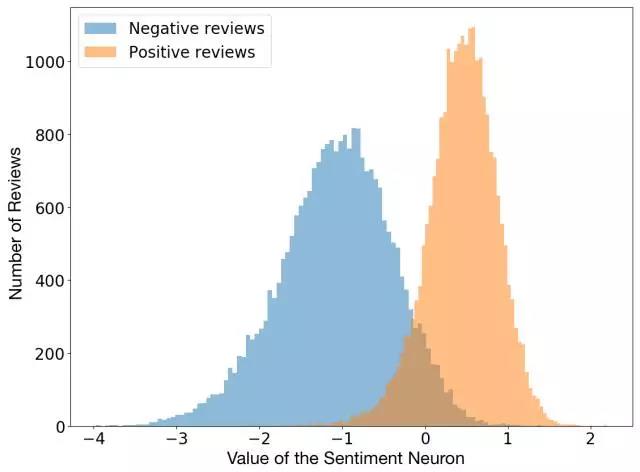
在用L1正則化訓(xùn)練線性模型的同時(shí),我們注意到,它使用了的學(xué)習(xí)單位令人意外的少。深入挖掘后,我們意識(shí)到,實(shí)際上存在著一種高度預(yù)測(cè)情緒值的“情感神經(jīng)元”。

我們模型中的情緒神經(jīng)元可以將評(píng)論歸為負(fù)面或正面,即使模型只是被訓(xùn)練來預(yù)測(cè)文本中的下一個(gè)字符。


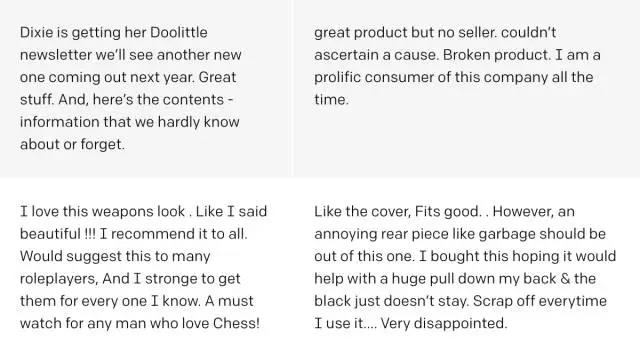
就像類似的模型一樣,我們的模型可以用來生成文本。與這些模型不同,我們用直接撥號(hào)(direct dial)來控制產(chǎn)出文字的情緒:我們只是重新設(shè)置了情緒神經(jīng)元的value。
由訓(xùn)練模型生成的合成文本的示例。以上,我們?cè)诖_定情緒單元的value后,從模型中選擇隨機(jī)樣本,以確定評(píng)論中的情緒。下面,我們還通過模型傳遞前綴“我無法弄清楚”,并選擇高相似度樣本。
例子
下圖表示情緒神經(jīng)元的字符到字符的符值(value),負(fù)值顯示為紅色和正值為綠色。請(qǐng)注意,像“最好的”或“可怕”這樣強(qiáng)烈的指示性詞語會(huì)引起顏色的特別大變化。

情感神經(jīng)元以字符到字符的值為基礎(chǔ),逐個(gè)調(diào)整其value。

有趣的是,在完成句子和短語之后,系統(tǒng)也會(huì)進(jìn)行大量更新。例如,在“約有99.8%的電影丟失”中,即使“影片中”本身沒有任何情緒內(nèi)容,“丟失”還有更新更新的消息。
無監(jiān)督式學(xué)習(xí)
標(biāo)簽數(shù)據(jù)是今天機(jī)器學(xué)習(xí)的燃料。收集數(shù)據(jù)很容易,但可擴(kuò)展標(biāo)記數(shù)據(jù)很難得到。人們一般在性價(jià)比可觀,或者重要程度夠高的問題上才會(huì)去給數(shù)據(jù)做標(biāo)簽,比如,機(jī)器翻譯,語音識(shí)別或自駕駕駛。
機(jī)器學(xué)習(xí)研究人員長期以來一直夢(mèng)想著開發(fā)無監(jiān)督的學(xué)習(xí)算法來學(xué)習(xí)數(shù)據(jù)集的良好表征,然后可以僅使用幾個(gè)標(biāo)記的例子就能解決任務(wù)。
我們的研究證明。在創(chuàng)建具有良好表征學(xué)習(xí)能力的系統(tǒng)時(shí),在大量的數(shù)據(jù)中,簡單地訓(xùn)練一個(gè)大型的非監(jiān)督式“下一步”預(yù)測(cè)模型,可能是一種很好的方法。
下一步:邁向通用無監(jiān)督表征學(xué)習(xí)
我們的結(jié)果對(duì)于邁向通用無監(jiān)督表征學(xué)習(xí)(general unsupervised representation learning)是很有希望的一步。我們探索通過語言建模是否可以學(xué)習(xí)到優(yōu)質(zhì)表征,從而找到結(jié)果,并在精心挑選的數(shù)據(jù)集上擴(kuò)大現(xiàn)有模型。然而,潛在的現(xiàn)象并沒有變清晰,反而更神秘了。
這些結(jié)果對(duì)于長文檔的數(shù)據(jù)集不是很強(qiáng)。我們懷疑我們的字符級(jí)別模型努力記住了數(shù)百到數(shù)千個(gè)時(shí)間段的信息。我們認(rèn)為值得嘗試用層次模型以適應(yīng)他們的時(shí)間尺度。進(jìn)一步擴(kuò)大這些模型可能進(jìn)一步提高表征、情緒分析和類似任務(wù)的保真度和性能。
這一模型處理越來越多的輸入文本與評(píng)論數(shù)據(jù)分歧。值得驗(yàn)證的是,擴(kuò)展文本樣本的語料庫可以獲得同樣適用于更廣泛領(lǐng)域的信息表征。
我們的研究結(jié)果表明,存在一種設(shè)置使得超大的下一步預(yù)測(cè)模型(next-step-prediction models)能學(xué)到很好的無監(jiān)督表征。訓(xùn)練一個(gè)大型神經(jīng)網(wǎng)絡(luò)以預(yù)測(cè)大量視頻集合中的下一幀可能會(huì)得到對(duì)于對(duì)象、場景和動(dòng)作分類器的無監(jiān)督表征。
總的來說,了解模型的性質(zhì)、訓(xùn)練方式和能夠?qū)е氯绱藘?yōu)秀的表征的數(shù)據(jù)集,這是非常重要的。
論文:

摘要
我們探索字節(jié)級(jí)遞歸語言模型的屬性。當(dāng)給予足夠的空間、訓(xùn)練數(shù)據(jù)和計(jì)算時(shí)間,這些模型學(xué)習(xí)到的表征可以包括對(duì)應(yīng)于高級(jí)概念的解決特征(disentangled features)。具體來說,我們找到一個(gè)執(zhí)行情緒分析的單位。這些以無監(jiān)督方式學(xué)習(xí)的表征,在 the binary subset of the Stanford Sentiment Treebank上達(dá)到頂尖的效果。它們處理數(shù)據(jù)效率也很高。當(dāng)僅使用少量標(biāo)簽的示例時(shí),我們的方法與在完整數(shù)據(jù)集上訓(xùn)練的強(qiáng)大基準(zhǔn)線的性能相當(dāng)。我們也展示了情感單位對(duì)模型的生成過程有直接的影響。簡單地將其值設(shè)置為正或負(fù),生成具有相應(yīng)正或負(fù)情緒的樣本。
OpenAI:我們開發(fā)了一個(gè)非監(jiān)督的系統(tǒng),能夠很好地表征情感。雖然研究中只是用亞馬遜網(wǎng)站上的評(píng)論進(jìn)行了訓(xùn)練,用于預(yù)測(cè)下一個(gè)字母。
一個(gè)線性模型使用這一表征,在一個(gè)小型但是被深度研究過的數(shù)據(jù)集 Stanford Sentiment Treebank上,獲得了當(dāng)下行業(yè)內(nèi)最高的情感分析準(zhǔn)度( 準(zhǔn)確率達(dá)到91.8%,此前最好的只有90.2%),并且,這一非監(jiān)督式的學(xué)習(xí)系統(tǒng),在性能上也能與此前的監(jiān)督式學(xué)習(xí)系統(tǒng)相媲美,使用的標(biāo)簽樣本要少30-100倍。我們的表征還包含了一個(gè)獨(dú)特的“情感神經(jīng)元”(distinguish emotional neurons),這一神經(jīng)元中包含了幾乎所有的情感信號(hào)。
標(biāo)簽訓(xùn)練樣本
我們的系統(tǒng)擊敗了 Stanford Sentiment Treebank 數(shù)據(jù)集上的最佳的方法,同時(shí)使用的數(shù)據(jù)量有大幅地減少。
標(biāo)注示例的數(shù)量需要我們模型的兩個(gè)變體(綠色和藍(lán)色線條),以配合完全監(jiān)督的方法,每個(gè)訓(xùn)練有6,920個(gè)例子(虛線)。
我們的L1正則化模型(在亞馬遜評(píng)論中以無監(jiān)督的方式預(yù)先訓(xùn)練)將多通道CNN性能與11個(gè)帶標(biāo)記的示例相匹配,并且使用最先進(jìn)的 CT-LSTM Ensembles與232個(gè)例子相匹配。
我們非常驚訝地看到,我們的模型學(xué)習(xí)了一個(gè)可解釋的特征,并且通過發(fā)現(xiàn)情感概念,簡單地預(yù)測(cè)出亞馬遜評(píng)論中的下一個(gè)字符。我們認(rèn)為這種現(xiàn)象不是我們的模型所特有的,而是一些大型神經(jīng)網(wǎng)絡(luò)的通用性質(zhì),這些大型神經(jīng)網(wǎng)絡(luò)被訓(xùn)練來預(yù)測(cè)其輸入中的下一步或維度。
方法
我們首先在8200萬亞馬遜評(píng)論的語料庫上訓(xùn)練了4,096個(gè)單位的乘法LSTM,以預(yù)測(cè)一小段文本中的下一個(gè)字符。整個(gè)訓(xùn)練在四個(gè)NVIDIA Pascal GPU上花費(fèi)了一個(gè)月的時(shí)間,我們的模型處理速度為每秒12,500個(gè)字符。
這4,096個(gè)單位(只是浮標(biāo)的向量)可以被認(rèn)為是表示模型讀取的字符串的特征向量。在訓(xùn)練mLSTM后,我們采用這些單位的線性組合將模型轉(zhuǎn)換為情感分類器,通過可用的監(jiān)督數(shù)據(jù)學(xué)習(xí)組合的權(quán)重。
獨(dú)一無二的情感神經(jīng)元
在用L1正則化訓(xùn)練線性模型的同時(shí),我們注意到,它使用了的學(xué)習(xí)單位令人意外的少。深入挖掘后,我們意識(shí)到,實(shí)際上存在著一種高度預(yù)測(cè)情緒值的“情感神經(jīng)元”。
我們模型中的情緒神經(jīng)元可以將評(píng)論歸為負(fù)面或正面,即使模型只是被訓(xùn)練來預(yù)測(cè)文本中的下一個(gè)字符。
就像類似的模型一樣,我們的模型可以用來生成文本。與這些模型不同,我們用直接撥號(hào)(direct dial)來控制產(chǎn)出文字的情緒:我們只是重新設(shè)置了情緒神經(jīng)元的value。
由訓(xùn)練模型生成的合成文本的示例。以上,我們?cè)诖_定情緒單元的value后,從模型中選擇隨機(jī)樣本,以確定評(píng)論中的情緒。下面,我們還通過模型傳遞前綴“我無法弄清楚”,并選擇高相似度樣本。
例子
下圖表示情緒神經(jīng)元的字符到字符的符值(value),負(fù)值顯示為紅色和正值為綠色。請(qǐng)注意,像“最好的”或“可怕”這樣強(qiáng)烈的指示性詞語會(huì)引起顏色的特別大變化。
情感神經(jīng)元以字符到字符的值為基礎(chǔ),逐個(gè)調(diào)整其value。
有趣的是,在完成句子和短語之后,系統(tǒng)也會(huì)進(jìn)行大量更新。例如,在“約有99.8%的電影丟失”中,即使“影片中”本身沒有任何情緒內(nèi)容,“丟失”還有更新更新的消息。
無監(jiān)督式學(xué)習(xí)
標(biāo)簽數(shù)據(jù)是今天機(jī)器學(xué)習(xí)的燃料。收集數(shù)據(jù)很容易,但可擴(kuò)展標(biāo)記數(shù)據(jù)很難得到。人們一般在性價(jià)比可觀,或者重要程度夠高的問題上才會(huì)去給數(shù)據(jù)做標(biāo)簽,比如,機(jī)器翻譯,語音識(shí)別或自駕駕駛。
機(jī)器學(xué)習(xí)研究人員長期以來一直夢(mèng)想著開發(fā)無監(jiān)督的學(xué)習(xí)算法來學(xué)習(xí)數(shù)據(jù)集的良好表征,然后可以僅使用幾個(gè)標(biāo)記的例子就能解決任務(wù)。
我們的研究證明。在創(chuàng)建具有良好表征學(xué)習(xí)能力的系統(tǒng)時(shí),在大量的數(shù)據(jù)中,簡單地訓(xùn)練一個(gè)大型的非監(jiān)督式“下一步”預(yù)測(cè)模型,可能是一種很好的方法。
下一步:邁向通用無監(jiān)督表征學(xué)習(xí)
我們的結(jié)果對(duì)于邁向通用無監(jiān)督表征學(xué)習(xí)(general unsupervised representation learning)是很有希望的一步。我們探索通過語言建模是否可以學(xué)習(xí)到優(yōu)質(zhì)表征,從而找到結(jié)果,并在精心挑選的數(shù)據(jù)集上擴(kuò)大現(xiàn)有模型。然而,潛在的現(xiàn)象并沒有變清晰,反而更神秘了。
這些結(jié)果對(duì)于長文檔的數(shù)據(jù)集不是很強(qiáng)。我們懷疑我們的字符級(jí)別模型努力記住了數(shù)百到數(shù)千個(gè)時(shí)間段的信息。我們認(rèn)為值得嘗試用層次模型以適應(yīng)他們的時(shí)間尺度。進(jìn)一步擴(kuò)大這些模型可能進(jìn)一步提高表征、情緒分析和類似任務(wù)的保真度和性能。
這一模型處理越來越多的輸入文本與評(píng)論數(shù)據(jù)分歧。值得驗(yàn)證的是,擴(kuò)展文本樣本的語料庫可以獲得同樣適用于更廣泛領(lǐng)域的信息表征。
我們的研究結(jié)果表明,存在一種設(shè)置使得超大的下一步預(yù)測(cè)模型(next-step-prediction models)能學(xué)到很好的無監(jiān)督表征。訓(xùn)練一個(gè)大型神經(jīng)網(wǎng)絡(luò)以預(yù)測(cè)大量視頻集合中的下一幀可能會(huì)得到對(duì)于對(duì)象、場景和動(dòng)作分類器的無監(jiān)督表征。
總的來說,了解模型的性質(zhì)、訓(xùn)練方式和能夠?qū)е氯绱藘?yōu)秀的表征的數(shù)據(jù)集,這是非常重要的。
論文:
摘要
我們探索字節(jié)級(jí)遞歸語言模型的屬性。當(dāng)給予足夠的空間、訓(xùn)練數(shù)據(jù)和計(jì)算時(shí)間,這些模型學(xué)習(xí)到的表征可以包括對(duì)應(yīng)于高級(jí)概念的解決特征(disentangled features)。具體來說,我們找到一個(gè)執(zhí)行情緒分析的單位。這些以無監(jiān)督方式學(xué)習(xí)的表征,在 the binary subset of the Stanford Sentiment Treebank上達(dá)到頂尖的效果。它們處理數(shù)據(jù)效率也很高。當(dāng)僅使用少量標(biāo)簽的示例時(shí),我們的方法與在完整數(shù)據(jù)集上訓(xùn)練的強(qiáng)大基準(zhǔn)線的性能相當(dāng)。我們也展示了情感單位對(duì)模型的生成過程有直接的影響。簡單地將其值設(shè)置為正或負(fù),生成具有相應(yīng)正或負(fù)情緒的樣本。


-
分享本文到:
-
關(guān)注隨銳:

微信掃描,獲取最新資訊 -
聯(lián)系我們:
如果您有任何問題或建議,
請(qǐng)與我們聯(lián)系:
suiruikeji@suirui.com
 掃碼關(guān)注微信眾公號(hào)
掃碼關(guān)注微信眾公號(hào) 抖音掃一掃 關(guān)注隨銳
抖音掃一掃 關(guān)注隨銳 China
China
